
APAI - How to Build an AI Product
APAI S2 Issue 04 - Applied AI


“Hey Product Manager, we need to add AI into our product in 2024.”
If you got an email like this from your manager, read on.
If you are a product manager or have interest in product management, and want to know how to bring an AI product/solution to life, read on.
Product managers must act like a master puzzle maker, translator, head chef or conductor overseeing an orchestra. And when faced with something like AI taking the world by storm, guess who gets handed the task to figure things out via an email from their bosses? Yes, product managers. (ok, sometimes you get told in strategic meetings)
Did you get such email from your manager? Or were you told this into a meeting? Comment below, let me know.
Table of Contents
Predictive vs Generative AI Solutions
Product Manager’s opinionated guide to GenAI Solutions
Predictive vs Generative AI Solutions
There are two main AI Solutions out there:
Predictive
Generative
Predictive AI is what most large companies, governments and the military have been using when they actually deployed AI solutions in the not so distant past. An example is using facial recognition in airports. Another one is using predictive AI for financial markets or for industrial IoT purposes such as predictive maintenance.
Generative AI is what has been making the world all hot and bothered for past 18 months.
I talk a lot about hybrid AI solutions and I believe the future will see a strong convergence towards hybrid Gen/AI Solutions. OnDevice learning with various IoT applications will see significant growth in this area. E.g. Your Apple Watch monitors your health data, it makes predictions based on this data (predictive AI), but it will start talking to you so you can comprehend and make sense of the numbers (Generative AI).
Let’s focus on Generative AI.(there will be a hybrid writeup in the near future)
Specifically a very popular AI product currently is a Question/Answer search system. This is often called a “chatbot” and it retrieves data from an unstructured datasource based on natural language processing (NLP) capabilities. They do this by using a Large Language Model (LLM) such as GPT 4.x, Claude, LlaMA, etc…
2024 is well underway to move past simpleton chatbots; usage is evolving into more sophisticated AI applications, where the “chatbot” is merely one of the UI/UX methods to interact with the AI Application.
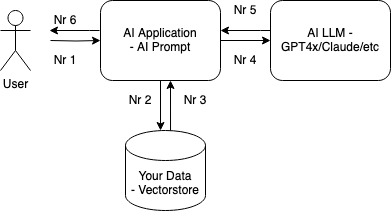
Simple Question/Answer data flow steps: User asks a question, AI app looks for similar text in the vectorstore, then the LLM responds based on user question and vectorstore data retrieved.
Here are some of the main issues with this approach that you need to be wary of:
AI Hallucinates with authority.
You pay $ everytime you make a call to an LLM - very important at scale.
Did I say, the AI Hallucinates with authority.
There’s a noticeable delay in responding to users (although GPT4 Turbo is freakishly fast TBH - fast does not mean accurate.) However, when searching for answers, often a user knows they asked the wrong question halfway through the LLM generating a response. This makes for bad UX.
LLM “colours outside the lines” - there’s no boundary and despite advances in prompting, it is not guaranteed to not say blatantly errnous things right in the middle of correct things. If the answer was totally wrong, it may be easier to spot, but it sandwiches bad answers in between 2 good answers. That makes it very hard to detect.
You need to make a call outside of your own application stack. This is surprisingly important at scale.
VERY High Security Risk - this approach exposes your system to prompt injection attacks which are incredibly effective.
Take Away: hallucinations and cost - these are the biggest reasons to want to not talk to an LLM.
Do you have any great examples of hilariously wrong answers AI has given you? Let’s hear:
The way to implement an AI Solution, evolve past simpleton chatbots, lower your production costs, starter costs and eliminate hallucinations:
TLDR: finetune the application’s response and eliminate the LLM in production use.
You do this via a multi-layer approach
Finetune the datasource in your vectorstore - this is a multi-phase process
Apply filtration on user prompts using UCIS (User Context/Intent/Sentiment)
Do not use LLMs in production - all answers should come from finetuned datasources.
(advanced) Have an AI support agent step in to guide user
(advanced) Apply filtration on all text generated by LLM (if you allow the AI agent to communicate using the LLM).
Step 1 - version 001
Load data in vectorstore, have a simple starter retrieval prompt and this is your basic AI application: every query you make will retrieve data, send it to LLM and you display the result to your user.
Pros:
Low initial costs, as text vectorization is inexpensive.
No need for specialized skillsets
Can you drag/drop PDF documents?
Congrats, you are ready to deploy a baseline AI application that does data retrieval.
Cons
This version will exhibit all the “bad” examples from the list above - ie. it will hallucinate with authority, it will cost you every time you use it, it is highly susceptible to injection atacks, etc.
To be useful for a business, at scale and to keep costs under control, you must finetune it further.
Step 2 - version 002
This is the meat and potatoes part of the process: finetune v001 of datasource.
Have a small set of powerusers/SMEs go through 80% of your use cases - e.g. take all your FAQs, onboarding docs, getting started videos (yes, audio transcripts, videos, images… just about anything can be vectorized). Ask the system, methodically, all the questions that are likely to give you a good/positive result.
When you get an answer you want, save that result in a new datasource vectorstore - (yes, you need a system that can 1) allow you to mark a good result and 2) it will start building v002 of the datasource based on “clean” answers that are human approved.))
This new version of the datasource will be tagged as v002.
All new inquires should fetch data from v002; setup result confidence score min threshold; if the system does not mee that min confidence score, then waterfall to v001 for retrieval. (This means the system should switch to v001 automatically, transparently in the background). An excellent vectorstore like Pinecone will return a result for a query in under 1 second. You should be able to query datasource v002 and v001 in under 1 second.
You are ready now for classifier training.
Pros
finer tuned datasource
high confidence score in answers
fixed cost to retrieve data from this version
Cons
you need to go through a comprehensive set of questions and answer verification as this will be used as the seed for the next version of data.
pay close attention to edge cases. this is most likely where you will spend most time/attention
Step 3 - version 003
Finetune further: create UCIS classifiers: User Context/Intent/Sentiment filters.
These are filters/labels that you create in the system to aid in finetuning and faster, higher precision data retrieval.
For example - here are 3 starter classifiers tags/filters:
- sales
- support
- general inquiries
Then run the Questions from Step2 again - fine tune the system and mark answers that fit in support or sales category, and leave general inquiries to be a catch all.
Anytime you save an answer, assign a classifier tag to that QA set. The classifier will be attached to that QA set.
This third refinement will catch nuanced edge cases, further help you cleanse your data in your datasource and will also let you add finer classifier filtration capabilities for your regular users.
Once you go through your use cases again you will have version 3 of the system.
You are ready to go live.
How does this new AI solution work vs the baseline chatbot solution?
User asks a question
» System runs UCIS classifiers and identifies the filtration tags.
»» System runs query against v003 of the system and uses UCIS classifiers to aid the vectorstore in filtration of data.
» System returns the vetted answer from v003 of database significantly faster than v001. No hallucinations in responses, significantly higher speed and consistent low processing time - thus contributing to a positive user experience.
Edge Cases
»»»» if no data found or low confidence score in v003, system queries v002
»»»» if no data found or low confidence score in v002, system queries v001
»»»» if nodata found or low confidence score in v001, an optimization technique is to pass on the workflow to a support AI agent if the system cannot find a satisfactory answer in v001. The purpose for this AI assistant is to identify anomaly usage patterns in the system and take action (e.g. same user keeps asking questions that take the system to v001 of the datasource)
Pros
no hallucinations
responses are guaranteed to be from a vetted dataset
low cost - no LLM production costs. Thus as your system grows, as your userbase grows, no need to worry about escalating LLM usage costs.
significantly improved user experience - retrieving pre-defined data is very fast. Not having to wait on an LLM to search and then hallucinate an answer is a much improved user experience.
consistent, deterministic answers - users will get the same consistent answer for the same type of input questions
Cons
higher long term cost - datasource should be consistently finetuned
Do you want to know more? Want me to do a deep dive for a vertical/use case? Comment below, let me know.